Scalable, Resilient Brainf∗ck
You probably shouldn’t read this article.
If you want to start learning a programming language - write a BF interpreter in it. For many years this has been a common suggestion to the newcomers into programming. And we all know how the typical solution would look like:
s[999],*r=s,*d,c;main(a,b){char*v=1[d=b];for(;c=*v++%93;)for(b=c%7?a&&(c&17?c&1?
(*r-=c-44):(r+=c-61):c&2?putchar(*r):(*r=getchar()),0):v;b&&c|a**r;v=d)main(!c,&
b-1);d=v;}
Well, or something a bit more readable in ~100 lines of code.
But, hey, that’s not how things should be done these days! First of all, the common truth is that “C is unsafe” and thus should be avoided at all costs. We are writing an interpreter, a serious and complex software, so Java, Go, Python, at least Rust would be a good start.
Then, every junior programmer knows that computers are unreliable, and such a critical tool as interpreter should not be run on a local machine. Better move it into the cloud from the beginning. Nothing says “I treat my software seriously” better than paying for its CPU usage from your own pocket.
And of course, monoliths are so old-school. Look, BF interpreter has been waiting for years to be semantically split into self-contained microservices. How about we take one to do the parsing, another moves the pointer and the third one increments and decrements memory cells? Sounds logical, and definitely reduces the complexity of the interpreter.
When we do the parsing - we need to take care about the loops. Ideally, we should put loop beginning address onto the stack and pop it when we need to jump back and repeat the loop. However, nobody in their sane mind would be writing such complex data structure as stack manually! Fortunately, quick googling shows that Redis already has lists and stacks implemented, and it’s a software with good reputation and many githib stars, so we’d better delegate handling stacks to it. Some trivial LPUSH/LPOP commands would do all the job and our service remains small and focused.
Moving the pointer is not so simple either. Where do we store the pointer value? I suggest we take a MongoDB and put a pointer as a document there. Yes, for now it’s just a single number, but who knows what else we would need to store in the future? We are lucky here, Mongo even has an $inc function to increment numbers, as if it was created to be used in BF interpreters! Talking to my SRE peers proves that if one has not got any weird problems with Mongo yet - they should definitely give it a try in production!
Finally, operations on memory cells. Whoa, this is hard. Memory is big and should be reliable. How about PostgreSQL? It’s battle tested, we can set up a few replicas. In fact, let’s go one step futher and think about performance. We can’t put all memory cells into one database. That would be slow. How about we put odd addresses in one and even addresses in the other? Such sharding should speed up things a little.
Obviously, we need some kind of a load balancer at front. And, we are done!
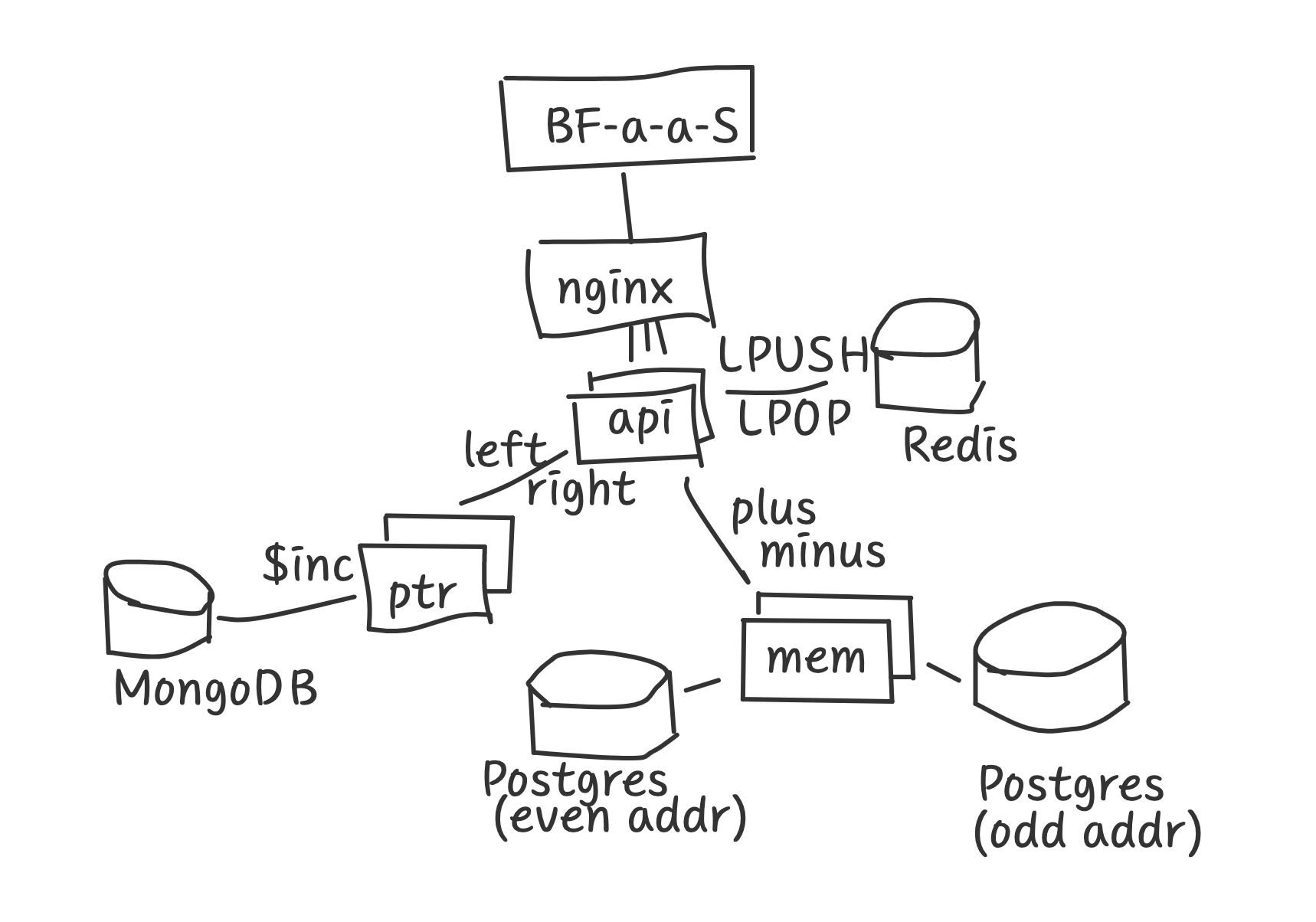
You think I’m joking? Here’s a prototype - https://github.com/zserge/bfapi - and it works much like we’ve designed above. Most of the code there was copied from StackOverflow, proving that it’s correct and we can skip writing tests and save us some time. In fact, the service runs a “hello world” script in only 400ms! That’s faster than a typical page loading on the web, proving that our design is a real improvement!
Enjoy, and please, think twice before adding complexity to the systems!
I hope you’ve enjoyed this article. You can follow – and contribute to – on Github, Mastodon, Twitter or subscribe via rss.
Apr 01, 2021
See also: A "Better C" Benchmark and more.
